支持向量机–SVM与核学习–kernel
原话说的是,主要考察思想…\ …你搁这搁这呢
讨论最基本的二分类的支持向量机(support vector machines,SVM),考虑训练样本集 D=(x1,y1),…,(xm,ym),yi∈−1,+1 。从最基本的超平面划分训练样本开始,导出 SVM 的基本问题,再利用对偶问题求解,最后讨论 SVM 的核技巧。
超平面
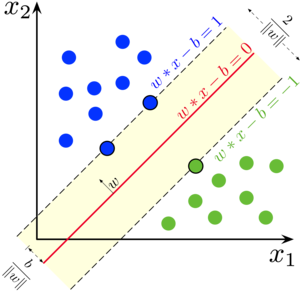
超平面(Hyper Plane) 是在样本空间中的一个平面。在我们熟悉的二维平面上, 一条直线的方程可以表示为 ax+by+c=0, 推广到多维的情况之后,超平面 可以用向量的形式表示为 w⋅x+b=0 , 记为 (w,b) 的形式,其中 w 是法向 量,而 b 为位移项。
考虑任意一点 x 到超平面之间的距离,可以表示为:
γ=∥w∥∣w⋅x+b∣
超平面能将样本空间划分成两部分。假设超平面 (w,b) 将所有样本正确分类, 即对于任意的 (xi,yi)∈D, 若 yi=+1 , 那么 w⋅x+b>0 , 若 yi=−1, 那 么 w⋅x+b<0。像这样的决策函数可以表示为:
yi=sign(w⋅xi+b)
那么,在一个空间中,会存在多个超平面能够将训练样本分开,那么究竟该努力去 找哪一个超平面呢?
.svg.png)
最大间隔
对于 (xi,yi), 可以将上面的距离公式的分子部分代入 yi 改写成:
γi=∥w∥yi(w⋅x+b)
定义间隔(margin)γ 为所有样本中离超平面最近的那个, 即 γ=minγi, 那 么 γi≥γ 总是成立的,代入上式可得:
∥w∥yi(w⋅x+b)≥γ
因此,SVM 的问题就变成了找到 “最大间隔”(maximum margin)的超平 面,使得 γ 最大,即:
max(w,b)mini∥w∥1∣w⋅xi+b∣ s.t. yi(w⋅xi+b)>0,i=1,2,…,m
因为间隔始终大于 0 , 即 ∣w⋅xi+b∣>0, 则可以通过缩放 (w,b) 使得 mini∣w⋅xi+b∣=1, 那么上面的问题就变成 max∥w∥1, 即 min∥w∥, 在其它书里通常会被等价成 min21∥w∥2, 于是上式可以重写成:
min s.t. 21∥w∥2yi(w⋅xi+b)≥1,i=1,2,…,m
是一个凸二次规划(convex quadratic programming)问题,这样就能够利用 上现有的求解优化问题的方法。(没错,就是一个运筹学的线性规划问题)
对偶问题
浅浅回顾一下
首先考虑一个最优化问题:
minf(z) s.t. hi(z)≤0
引入拉格朗日函数 L(z,α), 其中 α=(α1,…,αm),αi≥0 为拉格朗日乘 子,则有:
L(z,α)=f(z)+∑αihi(z)
那么上面的最优化问题等价于:
zminα≥0maxL(z,α)
称为 原始问题(primal problem。下面来证明其等价于一开始的优化问题,主要思路是将拉格朗日函数展开代入,再利用 α≥0 的条件消去第二项:
===zminα≥0maxL(z,α)zmin(f(z)+α≥0max∑αihi(z))zmin(f(z)+{0,∞, if hi(z)≤0 if hi(z)>0)zminf(z)
将该问题的中的 min 和 max 交换位置,即可得到其对偶问题(dual problem):
α≥0maxzminL(z,α)
原始问题与对偶问题的关系:
α≥0maxzminL(z,α)≤zminα≥0maxL(z,α)
在某些条件下,原始问题与对偶问题的最优值相等,这时候可以用解对偶问题代替 解原始问题。该条件称为 KKT(Karush-Kunh-Tucker)条件,具体证明超出了本文的涉及范围,我自己也不会,就先略过。在这个条件下,可以从 SVM 问题的 对偶问题 求解,进而得到 SVM 的解。
SVM 求解(99%
将 SVM 的问题用拉格朗日函数的形式重写为:
L(w,b,α)=f(w,b)21∥w∥2+∑αihi(w,b)≤0(1−yi(w⋅xi−b))
令 L(w,b,α) 对于 w 和 b 的偏导数等于零:
{∂w∂L=w−∑αiyixi=0∂b∂L=∑αiyi=0
可得:
w0=∑αiyixi=∑αiyi
将上式代入 L(w,b,α) 可得:
L(w,b,α)==21(∑αiyixi)⋅(∑αiyixi)+∑αi(1−yi((∑αiyixi)⋅xi−b)))i=1∑mαi−21i=1∑mj=1∑mαiαjyiyj(xi⋅xj)
这样,对偶问题就变成:
⟹α≥0maxzminL(z,α)α≥0maxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyj(xi⋅xj) s.t. ∑αiyi=0,αi≥0
解出 α 后,求出 w 与 b 即可得到模型:
f(x)=w⋅x+b=i=1∑mαiyi(xi⋅x)+b
具体求解过程需要满足上面提到的 KTT 条件:
⎩⎨⎧αi≥0yif(xi)−1≥0αi(yif(xi)−1)=0
求解上面的对偶问题 的一个著名算法是 SMO (Sequential Minimal Optimization), 这里不展开叙述。
软间隔
啥是软间隔,就是近似线性可分问题
上面我们考虑的都是数据可以分隔的情况,那么当数据集并不是完全能被超平面分 隔,即有些点不满足约束 yi(w⋅xi+b)≥1, 那可以设定一个惩罚项:
ξi=max{1−yi(w⋅xi+b),0}
那么原来的 SVM 的优化问题就会变成:
minw,b s.t. 21∥w∥2+C∑i=1mmax{1−yi(w⋅xi+b),0}1−yi(w⋅xi+b)≤0,i=1,2,…,m
其中的 max(1−z,0) 称为 “折页损失” (hinge loss)。接着引入 “松他变量” (slackvariable)ξi≥0, 将上式重写为:
s.t. minw,b21∥w∥2+C∑i=1mξiyi(w⋅xi+b)≥1−ξiξi≥0,i=1,2,…,m
即可得到 “软间隔支持向量机” (soft margin SVM)。求解方法与前面是一样的。
核方法(99%
ppt 看的头大
当遇到样本是 非线性可分 时,一般的线性 SVM 就无法很好的分类,这时候可以采用核技巧(kerneltrick)。
基本思想是 将样本映射至高维空间,变成高维空间中线性可分的即可。
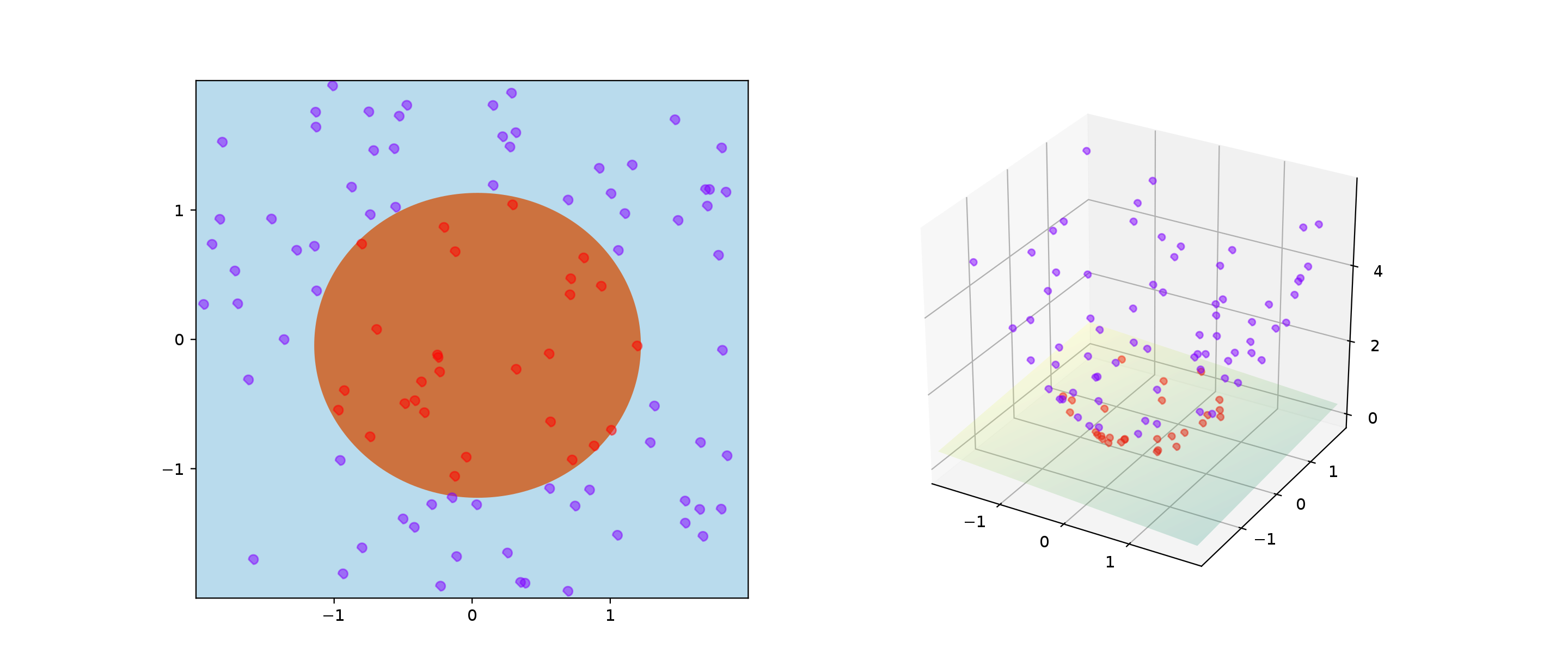
考虑一个映射函数 ϕ(x), 将 d 维特征映射至 m 维:
ϕ(x):Rd→Rm
定义 核函数(kernel function):
K(xi,xj)=ϕ(xi)⋅ϕ(xj)
核技巧的思想是用核函数 K 避免在高维 m 空间中计算映射函数的内积,这样能 够极大简化运算。
根据 Mercer′s theorem, 函数 K 能够满足成为核函数的充分必要条件是 K 是 半正定(positive semidefinite),即
i,j=1∑mcicjK(xi,xj)≥0
常用的核函数有 多项式核函数(Polynomial function):
K(xi,xj)=(xi⋅xj+1)d
以及 高斯核函数(Guassian radial basis function),通常称为 RBF Kernel:
K(xi,xj)=exp(−2σ2∥xi−xj∥2)